
I recently had a couple of Google interviews in Tokyo, and while preparing for them I ended up with a huge list of things I wanted to brush up on before the interview.
It turns out I didn’t get the job (next time!), but I thought I might be able to learn something anyway by working through the list and blogging about the main areas that companies like Google expect you to know.
Without further ado, first on the list is Big-O notation:
So what is Big-O notation anyway?
Big-O measures how well an operation will “scale” when you increase the amount of “things” it operates on.
Big-O can be used to describe how fast an algorithm will run, or it can describe other behaviour such as how much memory an algorithm will use. For the purposes of this article, we’re only going to focus on Big-O as it relates to runtime.
For example, deciding whether a number n is even or odd will take the same time no matter how big n is. On the other hand, to find an item in an unsorted list of n items, you have to look at each item individually - the time taken will increase as the size of the list increases.
Common complexity cases
Let’s have a look at a few different cases, and what they mean in real-world terms:
O(1)
O(1) means that no matter how large the input is, the time taken doesn’t change.
O(1) operations run in constant time. Some examples of O(1) operations are :
- Determining if a number is even or odd.
- Using a constant-size lookup table or hash table.
The following function will take the same time to execute, no matter how big array is :
def is_first_element_null(array)
if array[0] == nil
return true
else
return false
end
end
O(log n)
Any algorithm which cuts the problem in half each time is O(log n).
O(log n) operations run in logarithmic time - the operation will take longer as the input size increases, but once the input gets fairly large it won’t change enough to worry about. If you double n, you have to spend an extra amount of time t to complete the task. If n doubles again, t won’t double, but will increase by a constant amount.
An example of an O(log n) operation is finding an item in a sorted list with a balanced search tree or a binary search :
def binary_search(array, value, low=0, high=array.size-1)
# if high and low overlap, nothing was found.
return false if high < low
# Determine the middle element.
mid = low + ((high - low) / 2)
# Split the result in half and search again recursively until we succeed.
if array[mid] > value
return binary_search(array, value, low, mid-1)
elsif array[mid] < value
return binary_search(array, value, mid+1, high)
else
return mid # Found!
end
end
O(n)
O(n) means that for every element, you are doing a constant number of operations, such as comparing each element to a known value.
O(n) operations run in linear time - the larger the input, the longer it takes, in an even tradeoff. Every time you double n, the operation will take twice as long.
An example of an O(n) operation is finding an item in an unsorted list :
def contains_value(array, value)
for entry in array
return true if entry == value
end
return false
end
O(n log n)
O(n log n) means that you’re performing an O(log n) operation for each item in your input. Most (efficient) sort algorithms are an example of this.
O(n log n) operations run in loglinear time - increasing the input size hurts, but may still be manageable. Every time you double n, you spend twice as much time plus a little more.
Examples of O(n log n) operations are quicksort (in the average and best case), heapsort and merge sort.
def mergesort(list)
return list if list.size <= 1
mid = list.size / 2
left = list[0, mid]
right = list[mid, list.size]
merge(mergesort(left), mergesort(right))
end
def merge(left, right)
sorted = []
until left.empty? or right.empty?
if left.first <= right.first
sorted << left.shift
else
sorted << right.shift
end
end
sorted.concat(left).concat(right)
end
O(n^2)
O(n^2) means that for every element, you do something with every other element, such as comparing them.
O(n^2) operations run in quadratic time - the operation is only really practical up to a certain input size. Every time n doubles, the operation takes four times as long.
Examples of O(n^2) operations are quicksort (in the worst case) and bubble sort.
The following function is an example of an O(n^2) operation, where every element in an array is compared to every other element :
def contains_duplicates(array)
i = 0
while i < array.size
j = i + 1
while j < array.size
return true if array[i] == array[j] # Found a match!
j += 1
end
i += 1
end
return false
end
O(2^n)
O(2^n) means that the time taken will double with each additional element in the input data set.
O(2^n) operations run in exponential time - the operation is impractical for any reasonably large input size n.
An example of an O(2^n) operation is the travelling salesman problem (using dynamic programming).
O(n!)
O(n!) involves doing something for all possible permutations of the n elements.
O(n!) operations run in factorial time - the operation is impractical for any reasonably large input size n.
An example of an O(n!) operation is the travelling salesman problem using brute force, where every combination of paths will be examined.
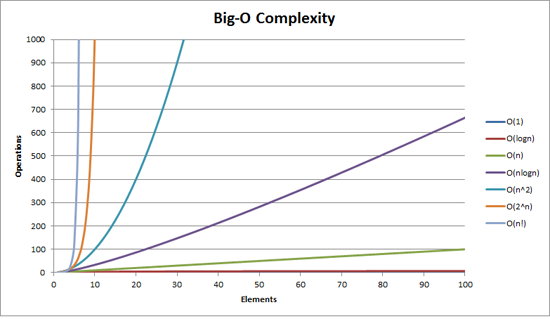
Big-O Visualized
The graph below[1] maps number of operations (on the X-axis) to time taken (on the Y-axis). It’s pretty clear that an O(2^n) algorithm is going to cause problems quickly as the input size increases!
Amortized analysis
Some operations are said to run in amortized time :
If you do an operation say a million times, you don’t really care about the worst-case or the best-case of that operation - what you care about is how much time is taken in total when you repeat the operation a million times.
So it doesn’t matter if the operation is very slow once in a while, as long as “once in a while” is rare enough for the slowness to be diluted away. Essentially amortised time means “average time taken per operation, if you do many operations”.
Let’s take [an] example of a dynamic array, to which you repeatedly add new items. Normally adding an item takes constant time (that is, O(1)). But each time the array is full, you allocate twice as much space, copy your data into the new region, and free the old space. Assuming allocates and frees run in constant time, this enlargement process takes O(n) time where n is the current size of the array.
So each time you enlarge, you take about twice as much time as the last enlarge. But you’ve also waited twice as long before doing it! The cost of each enlargement can thus be “spread out” among the insertions. This means that in the long term, the total time taken for adding m items to the array is O(m), and so the amortised time (i.e. time per insertion) is O(1). [2]
Exercises
Decide the Big-O complexity of the following examples :
def bubble_sort(list)
for i in 0..(list.size - 1)
for j in 0..(list.size - i - 2)
if (list[j + 1] <=> list[j]) == -1
list[j], list[j + 1] = list[j + 1], list[j]
end
end
end
return list
end
def factorial(n)
if n.zero?
return 1
else
return n * factorial(n - 1)
end
end
def bob_is_first(people)
return people.first == 'bob'
end
def palindrome?(input)
stack = []
output = ""
input.each_char do |x|
stack.push x
end
while not stack.empty?
output << stack.pop
end
return (output == input)
end
def sum_of_divisors(n)
result = 0
i = 1
while i < n
if n % i == 0
result += i
end
i += 1
end
return result
end
def is_prime(num)
return false if num == 1
return false if num == 2
for i in 2..(num-1)
if num % i == 0
return false
end
end
return true
end
def word_occurrence(word, phrase)
result = 0
array = phrase.split(' ')
for item in array
result += 1 if item.downcase == word.downcase
end
return result
end
Answers
- bubble_sort : Average and worst-case performance of О(n^2 ), where n is the number of items being sorted. This is because every element in the list is being compared to every other element. Performance of over an already-sorted list (best-case) is O(n).
- factorial : O(n) - the factorial function is called once for each element in the list.
- bob_is_first : O(1) - No matter how many people we pass to this function, the time taken won’t change, since we’re only looking at the first element.
- palindrome? : O(n) - a push() and pop() are performed for each character in the string, and naive string comparison (output == input) is also O(n).
- sum_of_divisors : O(n) - each number up to n is examined to determine if it is a factor.
- is_prime : O(n) - in the worst case (where num is prime), each potential factor will be examined.
- word_occurrence : O(n) - each word in the input phrase is compared to our target word.
Sources
- A Beginners’ Guide to Big O Notation (rob-bell.net)
- Amortized analysis (en.wikipedia.org)
- Big-O for Eight Year Olds? (stackoverflow.com)
- Big O notation (en.wikipedia.org)
- Constant Amortized Time (stackoverflow.com)
- Merge sort (en.wikipedia.org)
- Table of common time complexities (en.wikipedia.org)
- Time complexity graph (therecyclebin.wordpress.com)
{kind=link}
Footnotes
- Improved graph kindly provided by Xorlev The original graph was from The Recycle Bin
- Quote from Stack Overflow user Artelius